
用户需求分析分为两个方面,一个是搜索词分析,另外一个是用户搜索意图分析,通过搜索词的分析可以返回一个可能是用户需求的结果列表,通过用户搜索意图的分析并对搜索结果进行调整,可以获得此用户更加想要的结果列表。
搜索词分析:用户向搜索引擎提交一个查询后,搜索引擎会首先判断用户提交的搜索词类型是普通文本搜索、普通文本带有高级指令的搜索还是纯高级指令的搜索。这三类搜索词汇搜索引擎会分别进行不同的索引匹配。
首先我们先了解什么是纯高级指令搜索,年少有一篇文章就是专门讲高级指令的,大家可以直接点击SEO优化中一些高级搜索指令这篇文章进行了解,这里年少就不细讲了。
普通文本搜索:搜索引擎就会和处理网页内容一样先进行分词,去除停止词等处理,如果用户输入明显错误的字,搜索引擎还会依次进行矫正(注意:必须是错误汉字和矫正后的汉字是同一拼音,否则搜索引擎不会强制矫正)
普通文本带高级指令的搜索:这个一般搜索引擎首先会根据高级指令限定搜索范围,然后根据用户提交的文本搜索词,在限定范围内容进行检索和排名。
搜索意图分析
如果用户搜索一些比较宽泛的关键词时,如果只根据关键词本身,搜索引擎可能并不知道用户想要获取的是什么内容,这个时候搜索引擎就会尝试性的分析用户的搜索意图。比如说:“刘亦菲”,这个时候,搜索引擎并不知道用户是想要搜刘亦非的电影还是图片还是音乐了,这个时候,搜索引擎就会触发搜索引擎的整合功能,把刘亦菲的相关且不同方向的内容同时呈现出来,让用户自由选择,这样也可以保证在搜索结果的首页就能满足用户的需求。根据统计分析用户搜索该关键词的关注内容比率,搜索引擎也会调整这些内容的排名。
有的时候当用户搜索一些通用词汇的时候,搜索引擎会尝试参考用户所处地域的信息,返回可能是用户最需要的当地的相关信息。例如在武汉搜索饭店和在北京搜索饭店,得到的搜索结果首页一般都是当地“武汉信息”、“北京信息”。因为此类关键词一般都是在寻找本地信息。这也是搜索引擎分析用户搜索意图后对常规关键词的匹配搜索结果的改进。下图就是年少在武汉搜索饭店和网上的一个北京的朋友寒总搜索的饭店所截的图。
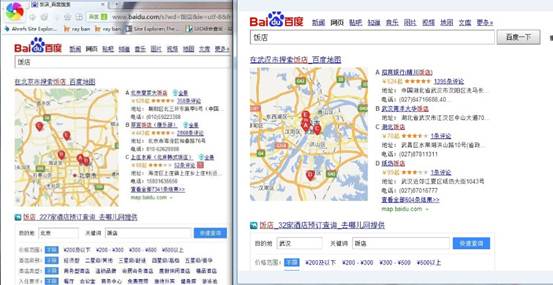
从上图中我们也看出来了搜索引擎在不断的改进,使得搜索结果的用户体验更加友好。
“刷点击”这个我想很多SEO人员都了解过,有的也干过吧,其实这也是搜索引擎的一个个性化搜索结果,如果有些网页被经常点击,搜索引擎就会通过Cookie记录用户的这一行为习惯,当用户搜索点击率达到一定的值后,搜索引擎就会优先把用户经常浏览的网页排在前面。这也就是后来很多人刷点击想要提升网页排名和关键词的排名。咳咳,当然,百度肯定又打击了一下。你懂的。老老实实的做SEO吧,骚年。
首发个人博客:年少轻狂
原创作者:年少
日期:2014.5.20
第二篇:基于用户行为分析的搜索引擎自动性能评价
ISSN1000—9825,CODENRUXUEW
JournalofSoftware,V01.19,No.11,November2008.PP.3023—3032
DOI:10.3724/SP.J.100I.2008.03023
o2008byJournalofSoftware.Allrightsreserved.E-mail:jos@iscas.ac.cnhttp://www.jos.org.cnTel/Fax:+86-10.62562563
基于用户行为分析的搜索引擎自动性能评价
刘奕群1+,岑荣伟1,张敏1,茹立云2,马少平1
1(清华大学计算机科学与技术系智能技术与系统国家重点实验室清华信息科学与技术国家实验室(筹),北京100084)
2(搜狐公司研发中心,北京100084)
AutomaticSearchEnginePerformanceEvaluationBasedonUserBehaviorAnalysis
LIUYi.Q衄1+,CENRong-Weil,ZHANGMinl,RULi-Yun2,MAShao-Pin91
1(TsinghuaNationalLaboratoryforInformationScienceandTechnology,StateKeyLaboratoryofIntelligentTechnologyandSystems,DepartmentofComputerScienceandTechnology,TsinghunUniversity。Beijing100084,China)
2(SohuIne.Research衄【dDevelopmentCenter。Beijing100084,China)
+Correspondingauthor:E-mail:yiqunliu@tsinghea.edu.皿.http:llwww.their.cn/group/一YQLie/
LluYQ,CenRW,ZhangM,RuLY,MaSP.Automaticsearchengineperformanceevaluationbasedouuserbehavioranalysh.JournalofSoftware,2008,19(11):3023-3032.http://wwwjos.org.cn/1000?9825/19/3023.htm
dataanalysis.anautomaticsearchengineperformanceevaluationmethodisAbstrlet:Withclick-through
proposed.Thismethodgeneratesnavigationaltypequerytopics
queryingandanswersautomaticallybasedonsearchuseruser8’andclickingbehavior.Experimental
aresultsbasedonacommercialChinesesearchengine’Slogsshowthattheautomaticmethodgetssimilarevaluationresultwiththetraditionalassessor-basedones.ThismethodCan
alsoprovidetimelyevaluationresultswithlittlehumanefforts.
KeyWOrds:Webinformationretrieval;performanceevaluation;userbehavioranalysis
摘要:基于用户行为分析的思路,提出了一种自动进行搜索引擎性能评价的方法.此方法能够基于对用户的查询和点击行为的分析自动生成导航类查询测试集合,并对查询对应的标准答案实现自动标注.基于中文商业搜索引擎日志的实验结果表明,此方法能够与人工标注的评价取得基本一致的评价效果,同时大大减少了评价所需的人力资源,并加快了评价反馈周期.
关键词:网络信息检索;性能评价;用户行为分析
文献标识码:A中图法分类号:TP393
检索系统的评价问题一直是信息检索研究中最核心的问题之一,Saracevic[1】指出.‘‘评价问题在信息检索研发过程中处于如此重要的地位,以至于任何一种新方法与它们的评价方式都是融为一体的".Kent首先提出了精确率.召回率的信息检索评价框架(根据文献【l】),随后,美国政府所属的研究机构开始大力支持关于检索评价
?SupportedbytheNationalNaturalScienceFoundationofChinaunderGrantNos.60621062,60503064.60736044(国家自然科学基金);theNationalBasicResearchProgramofChinaunderGrantNo.2004CB318108(国家重点基础研究发展计划(973));theNationalHigh.TechResearchand
ReceivedDevelopmentPlanofChinaunderGrantNo.2006AA012141(1l家高技术研究发展计划(863))2007-04-28;Accepted2007-08—24万方数据
JournalofSoftware软件学报V01.19,No.1l,November2008
方面的研究,而英国Cranfield工程在20世纪50年代末到60年代中期所建立的基于查询样例集、标准答案集和语料库的评测方案,则真正使信息检索成为了一门实证性质的学科,也由此确立了评价在信息检索研究中的核心地位川,其评价框架一般被称为Cranfield方法(aCranfield-likeapproach).
Cranfield方法指出,信息检索系统的评价应由如下几个环节组成:首先,确定查询样例集合,抽取最能表示用户信息需求的一部分查询样例构建一个规模恰当的集合:其次,针对查询样例集合.在检索系统需要检索的语料库中寻找对应的答案,即进行标准答案集合的标注;最后,将查询样例集合和语料库输入检索系统,系统反馈检索结果,再利用检索评价指标对检索结果和标准答案的接近程度进行评价,给出最终的用数值表示的评价结果.
Cranfield方法直到今天也被广泛地应用于包括搜索引擎在内的大多数信息检索系统评价工作中.由美国国防部高等研究计划署(Defense
(NationalInstituteofStandardsAdvancedResearchandProjectsAgency,简称DARPA)与美国国家标准和技术局Technology,简称NIST)共同举办的TREC(文本信息检索会
TestCollectionforIR议,http://trec.nist.gov/)就是一直基于此方法组织信息检索评测和技术交流的论坛.除了TREC以外。也有一些针对不同语言设计的基于Cranfield方法的检索评价论坛开始尝试运作,如NTCIR(NACSIS
Systems)计划与IREX(informationretrievalandextractionexercise)计划等.
随着万维网的不断发展与互联网信息量的增加,如何评价网络信息检索系统的性能逐渐成为近年信息检索评价中的热点关注方向,而在进行这方面的评价时,Cranfield方法遇到了巨大的障碍.困难主要反映在针对查询样例集合的标准答案标注上,根据Voorhees[2】的估计,对一个规模为800万文档的语料库进行某个查询样例的标准答案标注需要耗费9个评测人员一个月的工作时间.尽管Voorhees提出了像Pooling[2】这样的标注方法来缓解标注压力,但当前针对海量规模网络文档的答案标注仍然是十分困难的.如TREC海量规模检索任务(terabytetrack)一般需要耗费十余名标注人员2—3个月的时间进行约几十个查询样例的标注,而其语料库数据规模不过1000万文档左右.考虑到当前搜索引擎涉及到的索引页面都在几十亿页面以上(Yahoo!报告为192亿网页,中文方面Sogou声称的索引量也超过百亿),利用手工标注答案的方式进行网络信息检索系统的评价会是一个既耗费人力又耗费时间的过程.由于搜索引擎算法改进、运营维护的需要,检索效果评价反馈时间需要尽量缩短.因此提高搜索引擎性能评价的自动化水平是当前检索系统评价研究中的热点.
本文第1节讨论相关研究工作,阐明搜索引擎自动评价方面的已有工作成果和问题.第2节简要介绍查询信息需求与搜索引擎评价之间的关系.第3节对搜索引擎自动评价算法进行推导。并说明利用这种算法进行导航类查询自动评价的具体操作.第4节给出标准答案标注实验和性能评价实验结果.最后总结并列出主要结论.1相关研究工作概述
为了摆脱Cranfield方法在网络信息检索系统评价中所面临的困境,不少研究人员提出了一些自动进行搜索引擎性能评估的方案,其工作集中在两个方面:基于Cranfield框架,只是使用自动化方法进行答案自动标注;采用不同于Cranfield方法的评价框架进行自动化评价.
在前一个方面的研究工作中,研究者尝试使用检索系统反馈的结果信息进行自动标注.Soboroff等人【3】在基于TREC实验平台的研究中发现:评价人员对于结果池内文档的标注结果差异基本不影响检索系统性能排序的结果,因而随机挑选结果池内文档作为标准答案也有可能达到评价检索系统性能的作用.他们因而提出可以在检索系统结果池中随机挑选一定数量的结果作为答案集合进行评价.实验效果证明,以这种方式实现的检索系统评价结果与基于手工标注集合的评价结果正相关,但因对检索系统性能排序的影响较大而难以投入使用.Nuray等人【4】提出了对Soborofr方法的修正方案,即选择结果池中原本在搜索引擎结果序列中排序较靠前的文档作为标准答案,他们的方法也没有取得与手工评价方法相类似的评价结果.
我们认为,这类基于搜索引擎结果反馈信息(伪相关反馈信息)进行搜索引擎评价的尝试很难获得成功.这是由于伪相关反馈信息本身就是一种不可靠的信息源,它只能对搜索引擎处理性能较高的查询进行正确的结果标注,而事实上,由于针对这部分查询的评价不会对搜索引擎性能的提高起到指导作用,因此很少需要对其进行性能评价.这就形成了需要进行评价的查询标注得不好,不需要进行评价的查询反而标注得较好的情况。因此万方数据
刘奕群等:基于用户行为分析的搜索引擎自动性能评价
这种自动标注的思路很难应用于实际搜索引擎评价中.
也有部分研究人员基于已有的网页目录资源进行结果的自动标注,如Chowdhury[5】和Beitzel[6】提出的利用开放目录计划(ODP计划)所整理的网页目录和对应的网页摘要资源进行性能评测的工作.其方法的优势在于,答案标注的正确性比单纯使用搜索引擎结果反馈信息要高,但使用网页对应的摘要信息作为用户查询的模拟还是一个不合理的假设,因而其工作也没有得到大规模的普及应用.
在第二方面的研究工作中,比较有代表性的有IBMHaifa研究院研发的“相关词集合评价方法”与Joachims提出的基于用户点击行为的评价方法等.
Amitay等人【7】提出了“相关词集合评价方法(termrelevancesets。简称Trels方法)”.该方法首先选择一定量的代表用户查询需求的查询词;随后针对每一个查询词,手工标注尽量多的与此查询词相关联的词项;在进行评价时.通过待评测文档中关联词项的分布情况判定文档的相关程度及检索结果的可靠性.这种方法将大量手工工作从收集检索结果的过程之后转移到收集结果之前,他们也认为其标注的关联词项能够较长时间地发挥稳定的评价作用.Trels方法在一定程度上解决了评价结果反馈时间过长的问题,但丝毫没有减少甚至增加了相关性标注的难度.同时,词与词的相关程度本身就是一个难以界定的问题.Amitay等人基于TREC小规模数据的实验取得了一定的效果,但并没有将其应用于大规模的网络信息检索系统评价中.
Joachims[8J提出了使用用户点击行为信息评价搜索引擎性能的思路.他设计了一个元搜索引擎,用户输入查询词后,将查询词在几个著名搜索引擎中的查询结果随机混合反馈给用户,并收集随后用户的结果点击行为信息.根据用户不同的点击倾向性,就可以判断搜索引擎返回结果的优劣,Joachims同时证明了这种评价方法与传统Cranfield方法评价结果具有较高的相关性.由于记录用户选择检索结果的行为是一个不耗费人力的过程,因此可以避免传统Cranfield方法反馈过慢的问题.但在这之前,必须首先评判用户点击行为的可靠性,即用户的点击是否意味着其认为被点击的结果与查询相关.Joachims在这方面并没有给出一个完善的解决方案,其随机混合答案的方式尽管避免了所谓的“排序偏置”(1ip减少用户因为结果排列在前面就点击它的可能性),但也与用户正常使用搜索引擎的体验产生差异,因此收集到的用户行为可信程度降低;同时,使用这个元搜索引擎本身无法为用户带来更加快捷、方便的搜索体验,因此其必然无法吸引足够多的用户提供点击信息,进而影响到评价结果的可信程度.
综上所述。研究人员基于Cranfield框架进行了自动结果标注的尝试,但由于选择的标注方式不可靠而没有获得成功;在Cranfield框架之外进行的各种尝试,尽管其自动化程度都较高,但其评价方法的可靠性问题还有待商榷.我们认为,Cranfield的检索系统评价方式是经过相当程度的理论和实践检验的,因而在其面临搜索引擎评价的困境时将其抛弃是一种不明智的选择.而发展Joachims的用户点击行为分析方法,将其扩展到查询样例集合的结果自动标注过程中,是一个可行的解决方案.
2查询信息需求与自动性能评价
上一节,我们对搜索引擎自动评价的研究成果进行了综述,并提出了使用用户点击行为分析的方法进行答案自动标注的问题.这种想法的出发点在于:由于现有的绝大多数搜索引擎用户还是能够通过搜索引擎找到满足其查询需求的答案的(尽管可能需要花费较多的精力),因此用户的点击行为中肯定蕴含了其对检索结果相关性的评价.
从个体用户的行为上讲,有可能由于个人知识水平、网络使用习惯的不同而点击某些与查询需求无关的页面,甚至有可能被垃圾页面、SEO(searchengineoptimization)页面等所欺骗;但从用户群体的宏观行为规律上讲,这些无关点击可以通过被认为是随机噪声而滤除掉.因而当用户群体足够大、收集到的点击信息足够完善时,点击信息的可靠程度还是能够得到一定的保证的.
对于搜索引擎而言,其网络服务供应商的身份同时也为其收集了海量规模的用户日志信息.在之前的工作【9l中,我们利用这部分用户日志信息实现了用户查询信息需求的分类,因此,利用这些信息中蕴含的用户群体点击行为信息实现答案自动标注也是一个自然的解决问题的思路.万方数据
3026Journalof&胁软件学报V01.19,No.1l,November2008
然而,用户群体行为的可靠性尽管可以得到保证,但对于性能评价中的答案标注而言,标注出正确的结果并不是唯一需要考虑的问题,是否标注出了所有正确的结果同样值得考虑,这就需要具体考虑用户查询信息需求的问题.
Broder(2002)指出,用户的查询信息需求包括以下3类:
导航类(navigational):目标是查找某个特定的站点或者网页.如“上海市政府网站”、“清华大学招生简章”等(摘自百度网站“搜索风向标”栏目,下同).
信息类(informational):目标是获取可能位于一个或某几个网页上的信息.如“现代企业制度的形式”、“农村党员队伍状况”等.
事务类(transactional):目标是查找能够处理某些以Web为媒介的事务的网页.如“连连看下载”、“歌词查询”等.
对查询信息需求进行划分的出发点在于,针对3类检索可以使用不同的检索模型、参数,甚至评价方法也随着检索类别的变化而有所区别.因此,实现检索类别的自动划分对于提高检索性能和增加检索评价的可信度都具有非常重要的意义.
对于导航类查询而言,其正确答案唯一,因而无须考虑答案全面性的问题;其对应的搜索引擎检索性能也较高.因此用户点击行为的可靠性也比较容易保证.也就是说,用户在进行导航类查询时,比较容易发现并点击结果列表中对应的答案,因而我们所进行的主要工作只是将用户点击行为中反映出的答案挑选出来.对于信息或者事务类查询(统称信息事务类查询)而言,情况则要复杂得多,其正确答案不唯一,因此必须考虑答案全面性的问题:而其对应的搜索引擎检索性能相对较低,用户能否点击到即使是正确的答案也较难保证.
为了考察用户点击行为是否适用于进行信息事务类查询的答案标注,我们考察了提交查询词“电影”的4个常用中文搜索引擎(百度、谷歌、雅虎、搜狗)用户在2006年12月10日的点击情况,如图l所示.
O
O
O
O
0
0
OOI——+Baidu-a-Google+Y曲oo—}挚90“^|\^V\弱粥筋加协m:兮.、-|..{j|L—jL\L/、\/
123V—r力心.A√一一:X一:b.456789101112131415161718192021222324252627
Fig.IDifferencesinclick-throughbehavioroffourChinesesearchenginesusingkeyword“电影”(movie)
图l针对查询词“电影”的四个中文搜索引擎用户点击情况
实验收集了4个搜索引擎针对查询词返回的前lO位结果,取并集后共27个结果,图1中的横轴对应这27个结果,而曲线上的点则是结果对应的不同搜索引擎的用户点击频度信息.如第21号结果对应的搜狗搜索引擎曲线(用?.×”表示)上的数值约为34%,即代表第2l号结果在搜狗搜索引擎上被34%的查询“电影”的用户所点击.本实验数据的获得是通过搜狗公司采集的用户搜索反馈信息,共涉及了近200名用户的搜索引擎访问信息.
从图1中我们可以发现,不同搜索引擎用户针对这个查询的点击情况差异非常大,如百度用户的点击多集中在第l号结果上,而谷歌用户点击第3号和第10号的最多;各个搜索引擎的结果尽管有一定的交集,如第3、5、8号结果均被多个搜索引擎用户所关注,但其关注程度却有较大的差异.
尽管“电影”这个查询词仅仅是信息事务类查询的一个简单样例,但它可以反映出这种类型的查询需求对应的检索结果反馈现象:当提交同一个信息事务类查询需求时,用户在不同搜索引擎上得到的结果是不同的.这种差异既来源于搜索引擎的页面索引差异(即不同搜索引擎索引到的页面集合不同),也来源于搜索引擎的结果排序策略差异,因而对于查询目标页面不唯一的信息事务类查询是难以避免的.
这说明,对于信息事务类而言,用户期望的正确答案可能有多个,但某单个搜索引擎则很难反馈所有的结万方数据
刘奕群等:基于用户行为分析的搜索引擎自动性能评价
果。因此使用某个搜索引擎的用户行为信息去评价其他搜索引擎信息事务类查询的性能是不合理的.
对于研究人员而言,获取多家搜索引擎的用户日志有较高的难度,对于搜索引擎自身来讲,获取其他供应商的日志更是难上an难,因此在现有的实验环境和商业运行模式下,实现信息事务类查询的自动评价可能是不现实的选择.
3导航类查询的自动性能评价算法设计
在上一节的论述中,我们明确了在当前的实际应
用条件限制下,搜索引擎性能自动评价的对象只能限
制于导航类检索。因此本节我们来讨论导航类自动性
能评价系统的算法设计.依照Cranfield方法框架,查询
样例集合、标准答案集合和语料库是性能评价必备的
三要素,对于网络信息检索系统而言,Web数据集合即
其面对的语料对象,因此,实现查询样例集合和标准答
案集合的自动生成,就成为我们所主要关心的问题,包
括这两个环节在内的搜索引擎自动评价方法的整体运
行流程如图2所示.
搜索引擎日志首先经过数据预处理。获得必需的
用户点击行为特征,随后进行查询样例集合的自动选
取,并依据第2节所述的搜索引擎用户查询信息需求
分类方法进行查询需求分类,其中的导航类需求被挑
选进行自动标准答案标注,此后进行搜索引擎结果的
抓取和性能评价指标的计算.
在上述评测方法流程中,搜索引擎结果的抓取与过滤是指将查询样例集合中的样例提交给搜索引擎进行查询,并收集其结果页面,过滤出结果URL列表.而搜索引擎的性能评价指标计算则是指根据搜索引擎返回的结果URL列表与自动标注出的答案集合计算性能评价指标的过程.对于导航类查询需求而言,性能评价指标使用“首现正确结果排序倒数(reciprocalrank,简称RR)”进行计算.亩;。,SearchengineuserlogProcedureoftheautomaticsearchengineperformanceevaluationmethod图2搜索引擎自动评测方法流程
RR是指检索系统返回的结果序列中第1个满足用户需求的文档出现的序号的倒数.艘=1表示检索系统返回的结果中,第1个结果就可以满足用户需求.这个指标通常用来评价导航类检索的性能,因为这类检索只有1个标准答案可以满足用户需求.
3.1传统决策树算法处理关键资源判定的优势与困境
构建有合适代表性的查询样例集合对于搜索引擎评价结果的可靠性也是至关重要的.在传统的性能评价研究,如TREC相关工作中,查询样例集一般是由评测人员专门挑选出来的,部分任务的查询主题可能来自于对搜索引擎日志的筛选,但大部分是专门设计的用于评测系统性能的查询.此外,由于手工标注工作量的限制,查询样例集合的规模一般较小,每单个TREC检索任务的查询样例集合约包括几十个到一二百个查询不等.
由于我们所进行的是自动性能评测系统的查询样例集合设计,可以较少考虑人工标注所导致的查询数量限制,因此我们重点考察查询样例集合的代表性问题。即多大规模的样例集合足够代表搜索引擎用户的实际查询情况.为此,我们对Sogou搜索引擎2006年2月全月的用户日志集合进行了查询频度分析,分析结果如图3所示.
在图3中,我们选择了查询频度晟高的10000个查询词,并观察其频度的分布情况.图中的横坐标为按频度进行排序的序号,纵坐标为对应排序的查询的查询频度.从图中我们可以发现,频度绝对数值随排序增加而下降得非常迅速,这意味着少数查询即可能代表相当大的一部分用户的查询需求.根据统计,此查询词集合中频度高于100的查询仅有35177个,占查询总数目不足l%,但此l%的查询却覆盖了69%的用户查询需求.这说明使用万方数据
JournalofSoftware软件学报V01.19,No.11,November2008
一个较小规模的查询样例集合代表搜索引擎大部分用户的信息需求是完全可行的
1.0E+05
§7.5E+04
尝50E+04
百
吕2.5E+04
0.0E4-00
0IL200040006000800010000
Fig.3QueryfrequencydistributioninSogousearchenginelog
图3搜狗搜索引擎日志中的查询频度分布情况
尽管标准答案集合的标注将自动完成,但由于搜索引擎结果抓取速度受到网速、搜索引擎服务策略等多方面的限制,因此查询样例集合的整体规模不宜过大.考虑到实际施行难易程度和用户需求代表性两个方面的因素,我们认为选择约10000~15000个查询词作为查询样例集合较为合适.这个规模的样例集合能够代表相当大比例的用户需求(一个月用户需求总数的约50%),处理时间也可以接受(当程序运行硬件环境为1.8G主频CPU,1G内存,IOOMLAN的网络时,约需l天时间完成性能评估).
因此。选取一段时间内搜索引擎查询频度最高的一定数量查询,是我们构建查询样例集合的核心策略.
3.2连续属性值的离散化
与查询样例集合的自动生成相比,标准答案集合的标注是更为困难的研究课题.在第l节的论述中,我们也指出这个标注过程是Cranfield方法在评价搜索引擎性能时所面I临的最大困难.上一节中我们将查询样例集合的规模控制在lO000—15000查询左右,这个规模的样例集合对于手工标注答案而言是不可完成的任务,因此,构建快捷、准确的答案标注算法势在必行.
Lee等人【10]首先给出了点击集中度的定义,对于某个查询Q,定义尺,。为查询Q的搜索引擎用户点击得最多的一个结果,而点击集中度则为对应尺。。,的点击数与针对Q的总点击数的比例值.Lee提出点击集中度的概念,更多的是从查询信息需求分类的角度进行考虑,而我们把注意力转向对尺~,的考察.
对于导航类查询而言,由于用户的信息需求唯一,因而用户的点击一般会集中在其查询目标页面上,即R一,有很大可能成为查询目标页面.但当搜索引擎无法把查询目标页面反馈在结果序列中较靠前的位置时,由于Silversteintlll和余慧佳I”1指出的“绝大部分用户只点击第l页搜索结果”的情况,上述推断也可能出现错误.由于搜索引擎针对导航类查询的检索效果较好,在前一两页结果中没有返回查询目标页面的概率很小,因此这种推断错误的情况应该认为很少发生.
如果定义网页,.针对查询Q的“点击比率”为点击比率cQ,.,=主差是鬟笔摹毫昌等淼
点击比率(Q,R。)=点击集中度(Q)c-,则有下式成立:(2)
即点击集中度等于点击比率的最大值,而点击比率最大的,.则很可能成为导航类查询Q的查询目标页面.
依照上述推断,我们可以设计下面的标准答案自动标注算法:
对待标注的查询样例集合中给定的查询Q及其被点击过的查询结果rI,r2,...,w
球Q为导航类查询
在,l,r2,...,~中定位尺,使其满足点击比率(Q固=点击集中度(Q);
Ⅲ点击集中度(Q)>r标注R为Q的标准答案:万方数据
刘奕群等:基于用户行为分析的搜索引擎自动性能评价3029
EXIT;
ELSE
Q不可被标注;
ENDIF
ELSE//Q不是导航类查询
Q不可被标注;
ENDIF
在算法过程中.设计点击集中度最小阈值r的目的在于避免出现前文提到的搜索引擎无法把查询目标页面反馈在结果序列中较靠前的位置的情况,在这种情况下,无法依靠用户行为日志实现答案的自动标注,因此,算法需要给出对应的提示信息.
4实验与结果分析
4.1实验环境和方法简述
本节针对上述提出的搜索引擎自动性能评价算法,利用实验方法验证其可靠性.实验数据采集自Sogou搜索引擎2006年6月~2007年1月半年多的查询、点击日志,每日的查询和点击行为数量约为150万条.采用海量真实规模搜索引擎数据进行算法有效性的验证,可以充分考察算法的可靠性及施行效率.
如上文所述,实验所采用的硬件平台是一台普通PC级别计算机,整体花费约6000元人民币,实验在100M局域网内进行.算法的时间花销主要集中在待评测搜索引擎结果序列的抓取上,每小时处理的查询个数约为400个.这与传统性能评价工作中十几个标注人员工作数月的效率相比,有了质的飞跃.
下面我们将分别从标准答案标注的正确性与性能评价指标的准确性两方面来衡量搜索引擎自动评价算法的性能.
4.2答案自动标注实验结果
为了控制查询样例集合的规模,同时考察算法针对用户行为时间变化的鲁棒性,我们没有整体使用上述日志数据,而是将实验所用的用户行为日志数据按时间段分成3部分,分别施行查询样例提取和标准答案标注.针对每个部分的答案标注结果,我们随机抽取约5%的数据进行手工验证,实验结果见表1.
Table1Automaticanswerannotationexperimentalresults
表1答案自动标注实验结果
!i堡!P!盟!!
2006.6~2006.8
2006.9~2006.11
2006.12-2007.1!!垄!!!!!!!塑P!!g!璺!!塾139021388411296!i!!垡!!!!笪!!壁695694565垒坚!!!!!f竖298.1397.4196.64
每个时间段导航类查询样例集合的规模都控制在10000—15000个查询范围之内,最后一个时间段的时间跨度略短,因此集合规模也略小.而手工验证的实验结果则说明,答案标注的准确度相当高,每个样例集合的标注精确率都超过了95%,考虑到即使手工标注也很难避免错误,自动答案标注可以说满足了搜索引擎性能自动评价的需要.
我们进一步分析了若干标注错误的样例,发现绝大部分的错误都是如下情况导致的:正确结果应当是某个站点的主页,而自动标注的结果为此站点的某个子站点主页.例如,查询“163”对应的标准答案应当是http://www.163.com,而自动标注的答案是http://mail.163.corn;查询“搜狗”对应的标准答案应当是http://www.sogou.corn,而自动标注的答案是http://d.sogou.com.
通过进一步分析我们发现,这种自动标注答案发生错误的情形是由用户点击行为的倾向性所造成的.由于绝大部分用户事实上并非想访问其查询词对应的站点主页,而是这个站点最具吸引力的某个子站点首页,因此,主页的用户点击集中度反而不及子站点首页高.查询“163”的用户大都点击了其邮箱主页是因为163的免费邮万方数据
3030JournalofSoft臃软件学报V01.19,No.11,November2008箱服务是中文网络环境中最受欢迎的,而搜狗mp3搜索比搜狗网页搜索产品质量更高也是一般网络用户的共识..
因此,这种错误的产生事实上并不是自动标注算法的谬误,而是用户的真实行为和选择倾向性的体现.从这个角度讲,是否只有标注站点主页才算标注正确也是值得商榷的问题,但这并非本文讨论的重点.在下文的实验中,我们还是以传统意义上的主页作为查询对应的标准答案.
4.3性能评价实验结果
按照第3节中所述的搜索引擎自动性能评价方法即可自动生成性能评价所需的查询样例集合和标准答案集合。并使用Cranfield方法对搜索引擎的处理导航类查询需求的性能进行评价.
我们选用了搜狗搜索引擎之外的5个中文搜索引擎作为性能评价的对象,它们是:百度、谷歌、雅虎中文、新浪爱问搜索与中国搜索.我们之所以没有选择提供用户行为日志的搜狗搜索作为被评价的目标,是考虑到用户行为日志的提供者有可能在评价的过程中被给予不应有的偏向.
在评价指标方面,我们选择了“首现正确结果排序倒数”(参见第3节)指标进行性能计算与比较.而为了验证评价实验效果的正确性,我们也建立了一个手工评价集合与自动评价结果进行比较.
手工评价的查询样例集合由评价人员从查询日志中手工挑选的320个导航类查询词组成.查询样例集合被投入上述5个搜索引擎进行查询并收集结果,将结果取并组成结果池,并使用pooling方法由评价人员进行答案标注,以此获得了查询样例对应的标准答案集合和进一步的搜索引擎评价结果.
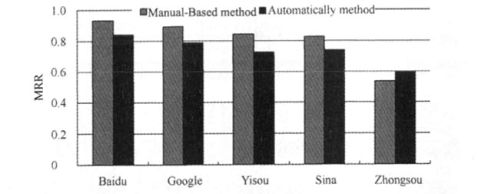
具体的评价实验结果如图4所示.图4介绍了搜索引擎自动评价的实验结果,并将其与手工评价结果进行了比较.由图4可知,自动评价的搜索引擎性能排序结果与手工评价的结果完全相同,两种方法给出的MRR值之间的相关系数为O.965。这意味着两种方法给出的评价结果非常相似.
Fig.4Comparisonbetweenautomaticandmanualperformanceevaluationresults
图4搜索引擎自动性能评价结果与手工评价结果的比较
从图中我们可以看出,尽管从总体性能评价排序而言,手工方法与自动评价方法保持一致,但两种评价方式是由于其手工选择的样例较少,可能都是搜索引擎处理得较好的样例,因而性能绝对数值都较高;而自动评价所
正如我们在第l节中所介绍的,我们的研究工作并不是首次把用户行为信息应用到搜索引擎评价中的尝中上述的搜索引擎自动评价方法.
利用用户行为信息进行搜索引擎评价的工作容易被两方面的问题所困扰,其一是我们已经提到的用户点
万方数据对应的MRR绝对数值却有一定差别.这是由所采用的查询样例集合不一致造成的,手工评价的MRR数值较高,选用的样例数量多(是手工评价样例的40倍以上),代表性好,其数值更能反映搜索引擎的实际处理能力的高低.4.4实验结果讨论试,Joachimsl8J就提出了利用元搜索引擎接口评价搜索引擎性能的思路,但我们对以往工作中的核心假设,即用户点击的结果即为相关结果产生了怀疑,这促使我们从宏观而不是从个体的角度考察用户行为,并提出了本节击的可信度问题,其二是行为信息提供者(在本文的工作中即为搜狗搜索)本身的评价问题.
刘奕群等:基于用户行为分析的搜索引擎自动性能评价3031对于第l类问题。用户个体的点击行为确实容易受到多种因素的干扰而发生偏移.这是由于用户的点击行为是基于搜索引擎返回结果的标题与部分摘要文字作出的,但标题和摘要文字却无法完整地代表网页全貌,甚至有部分标题与摘要被专门设计用于欺骗用户点击(这在SEO操作中屡见不鲜),这就使个体用户点击行为的质量变得更为不可信.
但宏观而言,用户群体的点击行为还是可以信任的,如果某个页面吸引大量用户进行点击,但其并不是真正的查询目标页面,则这个页面要么是我们上文提到的与查询目标页面相关的同样吸引用户的一个页面;要么则是设计得极为出色的垃圾页面.从搜索引擎设计的角度来看,这样的垃圾页面会对用户体验造成毁灭性的打击,因此一般会被及时处理。而不会对用户的行为产生过大的影响.因此,用户群体在一定长度时间段内的行为特征是值得信任的.我们在本节的实验结果也充分验证了这一点.
对于第2类问题,我们认为用户行为信息的提供者不适合同时作为被评价的对象.这是因为作为日志提供者的搜索引擎在评价过程中会具有评价偏向:由于只有出现在日志提供者索引中的网页才有可能被选择为标准答案,因此未出现在日志提供者索引中的正确答案也不可能被标注,即使其他搜索引擎返回了这样的答案,自动评价方法也无法辨识.例如http://www.sysu.edu.c“和http://www.zsu.edu.c“是中山大学主页的两个不同镜像,因此均应当被标注为“中山大学”的标准答案,但由于只有后者出现在了搜狗搜索引擎的索引中,因此只把前者作为查询结果返回的搜索引擎自然会被给予不合理的评价.这也正是我们没有在第4.3节的实验中纳入搜狗搜索引擎作为被评价对象的原因.
5结论与未来工作
性能评价一直是信息检索系统研究中的核心问题之一,传统的基于标准语料库、查询样例集合和标准答案集合的Cranfield方法在处理搜索引擎的性能评价问题上面临着巨大的困难.基于用户查询点击行为挖掘的方法自动化的评价搜索引擎的查询性能是本文所要解决的主要问题.
为了提高检索系统查询处理能力,我们提出基于用户群体行为分析的搜索引擎自动评价方法.该方法利用搜索引擎用户查询、点击行为的宏观分析,自动挑选适用于搜索引擎评价的查询集合,并进一步自动定位对应这些查询的标准答案.由于挑选查询集合和标准答案的过程由计算机自动完成,因此可以及时、准确、客观地反映搜索引擎的真实性能.
利用海量规模搜索引擎网络日志数据的实验结果表明,上述基于用户群体行为分析的搜索引擎自动性能评价方法能够自动提取用户查询需求样例,并准确标注超过95%的导航类查询答案.针对中文搜索引擎性能评价的实验也发现,该自动方法性能评价的结果与手工评价的结果具有很高的一致性.与传统的手工评价方法相比,自动评价方法具有及时、客观、准确、全面的特点.
综上所述,我们基于用户群体行为分析的思路实现了一种有效的搜索引擎性能自动评价方法,该方法适应大规模网络信息检索系统的应用需求,同时能够客观、准确地实现搜索引擎系统的自动性能评价.
References:
【1jSaracevicT.Evaluationofevaluationininformationretrieval.In:Fox
Int’lEA,IngwersonP,Fidelkeds.Prc虻.ofthe18thAnnualACMSIGIRConf.onResearchandDevelopmentinInformationRetrieval(SIGIR’95).NewYork:ACMPress.1995.138-146.
【2】VonrheesEM.The
ofCross?Languagephilosophyofinformafionretrievalevaluation.In:PetersC,8raschlcrM,OonzaloJ’KluckM,eds.EvaluationInformationRetrievalSystems:SecondWorkshopoftheCross-LanguageEvaluationForum,CLEF2001.LNCS2406.2001.355—370.
【3】3SoboroffI,NicholasC,CahanP.Rankingretrievalsystemswithoutrelevancejudgments.In:KraftDH.CroftWB,HmperDJ,
24thAnnualInt’lACMSIGIRConf.彻ResearchandZobelJ.eds.Proc.oftheDevelopmentininformationRetrieval(SIGIR
2001).New
【4】NurayKYork:ACMPress.2001.66—73.F.Automaticrankingofretrievalsystemsinimperfectenvironments.In:ClarkeC,CormackG.CallanJ,HawkingD,Can
万方数据
3032JournalofSoftware软件学报V01.19,No.1l,November2008
SmeatonA.eds.Proc.ofthe26thAnnualInt’lACMSIGIRConf.onResearchandDevelopmentinInformationRetrieval(SIGIR2003).NewYork:ACMPress,2003.379—380.
【5】ChowdhuryA,SoboroffI.AutomaticevaluationofworldwideWebsearchservices.In:JarvelinkBeaulieuM,Baeza?YatesIL,
MyaengSH,eds.Proc.ofthe25thAnnualInt’lACMSIGIRConf.onResearchandDevelopmentinInformationRetrieval(SIGIR2002).NewYork:ACM
【61BeitzelPress,2002.421-422.SM,JensenEC,ChowdhuryA,GrossmanD.Usingtitlesandcategorynamesfromeditor?driventaxonomiesforautomatic
J,QureshiS,SeligmanL,eds.Proc.ofthe12thInt’lConf.onInformationandevaluation.In:KraftD,FriederO,Hammer
KnowledgeManagement.2003.17-23.
relevancesets.In:Jarvelinl('AllanJ.BmzaP,AmitayE.CarmelD。Lempelit,SofterA.ScalingIR—systemevaluationusingterm
SandersonM.eds.Proc.ofthe27thAnnualInt’lACMSIGIRConf.onResearchandDevelopmentin
(SIGIR2004).NewYork:ACMPress.2004.10—17.
隅】JoachimsT.Evaluatingretrieval
Springer-Verlag,2003.79—96.InformationRetrievalperformanceusingcliekthroughdata.In:FrankeJ.NakhaeizadehG,RenzI.TextMining.
【9】Liu
KanYQ。ZhangM,RuLY,MaSP.Automaticquerytypeidentificationbasedonclickthroughinformation.In:NgHT.LeongMK,MY,JiDH,eds.Proc.ofthe3rdAsiaInformationRetrievalSyrup.,AIRS2006.LNCS4182,Berlin,Heidelberg:Springer—Verlag.2006.593—600.
[10】LeeU,LiuZY。Cho
onJ.AutomaticidentificationofUSergoalsinWebsearch.In:EllisA,HaginoT。eds.Proc.ofthe14thInt’lConf.WorldWideweb.W'W3v2005.2005.ACMProc.ofthe14thInt’lConf.onWorldWideWeb(WWW2005).NewYork:ACMPress.2005.391--400.
SilversteinC,Marais
6一12.H,HanzingerM,MoriczM.AnalysisofaverylargeWebsearchenginequerylog.SIGIRForum,1999,33(1):
[12】YuHJ,Liu
InformationYQ,ZhangM,RuLY,MaSP.ResearchinsearchengineUSCTbehaviorbasedonloganalysis.JournalofChineseProcessing,2007,21(1):109一114(inChinesewithEnglishabstract).
附中文参考文献:
[121余慧佳.刘奕群,张敏,茹立云,马少平.基于大规模日志分析的网络搜索引擎用户行为研究.中文信息学报,2007,21(I):109-114
刘奕群(1981--),男,山东济南人,博士,助
理研究员。主要研究领域为信息检索,机器
学习.茹,'0"云(1979--)。男,博士生,主要研究领域为自然语言处理.网络信息检索.
岑荣伟0982--),男.博士生。主要研究领域
为信息检索,机器学习.马少平(1961--),男,博士,教授,博士生导师,CCF高级会员,主要研究领域为知识工
程,信息检索,汉字识别与后处理,中文古


籍数字化.张敏(1977一),女,博士,助理研究员,主要
研究领域为机器学习.信息检索.
万方数据



基于用户行为分析的搜索引擎自动性能评价
作者:
作者单位:刘奕群, 岑荣伟, 张敏, 茹立云, 马少平, LIU Yi-Qun, CEN Rong-Wei, ZHANG Min, RU Li-Yun, MA Shao-Ping刘奕群,岑荣伟,张敏,马少平,LIU Yi-Qun,CEN Rong-Wei,ZHANG Min,MA Shao-Ping(清华大
学,计算机科学与技术系,智能技术与系统国家重点实验室,清华信息科学与技术国家实验室
(筹),北京,100084), 茹立云,RU Li-Yun(搜狐公司研发中心,北京,100084)
软件学报
JOURNAL OF SOFTWARE
2008,19(11)
2次刊名:英文刊名:年,卷(期):被引用次数:
参考文献(13条)
1.Saracevic T Evaluation of evaluation in information retrieval 1995
2.Voorhees EM The philosophy of information retrieval evaluation 2001
3.Soboroff I.Nicholas C.Cahan P Ranking retrieval systems without relevance judgments 2001
4.Nuray R.Can F Automatic ranking of retrieval systems in imperfect environments 2003
5.Chowdhury A.Soboroff I Automatic evaluation of world wide Web search services 2002
6.Beitzel SM.Jensen EC.Chowdhury A.Grossman D Using titles and category names from editor-driventaxonomies for automatic evaluation 2003
7.Amitay E.Carmel D.Lempel R.Softer A Scaling IR-system evaluation using term relevance sets 2004
8.Joachims T Evaluating retrieval performance using clickthrough data 2003
9.Liu YQ.Zhang M.Ru LY.Ma SP Automatic query type identification based on click through information2006
10.Lee U.Liu ZY.Cho J Automatic identification of user goals in Web search 2005
11.Silverstein C.Marais H.Henzingcr M.Moricz M Analysis of a very large Web search engine query log1999(01)
12.Yu HJ.Liu YQ.Zhang M.Ru LY Ma SP Research in search engine user behavior based on log analysis[期刊论文]-Journal of Chinese Information Processing 2007(01)
13.余慧佳.刘奕群.张敏.茹立云.马少平 基于大规模日志分析的网络搜索引擎用户行为研究[期刊论文]-中文信息学报 2007(01)
相似文献(7条)
1.期刊论文 韩建.张金.蔡药迪.张博 新型网络信息检索工具简介及其性能评价 -中国科技博览2010,""(4)
近年来,网络信息检索的发展很快,新型的检索工具层出不穷,其中代表性的、倍受关注的是对等计算.对等计算在实践中的重要应用主要是信息资源共享.但随着对等计算信息检索系统的广泛应用,如何对其进行客观公正的评价,确定一个有效的、实用的评估标准已迫在眉睫.本文将以对等计算为主,探讨新型网络信息检索工具的使用及性能评价.我们详细研究分析了对等计算的信息共享系统后,指出目前P2P信息检索系统面临的实现机制和关键技术问题.经过认真总结和分析,得出评价系统性能的指标体系,提出系统性能评价的CTL定律,这对P2P信息检索系统的评价和开发将具有实际指导意义.同时,在此基础上确定今后对等计算信息检索系统研究工作的重点--关键技术及其相应策略.
2.会议论文 曾民族 网络信息检索现状和性能评价 1996
网络信息检索作为一种新型检索模式,主要特异性在于网络环境引起的信息资源分布化和数字技术带来的信息资源多媒体化,从而引起了信息检索过程各个要素的量变和质变。该文将考察信息资源的变化对信息检索提出的新的要求以及由此推动信息检索方式、信息界面、索引自动化、性能评价标准的变化,介绍当前网络信息检索工具尤其WWW查询引擎的发展现状和作为网络查询引擎核心技术的网络自动跟踪索引软件的有关发展,以及查询引擎性能的评价方法等问题。
3.期刊论文 何晓艳.朱俊东 搜索引擎性能评价 -华北煤炭医学院学报2010,12(2)
搜索引擎是当今网络信息检索的主要工具,它在满足人们从互联网上快速、准确、全面的获取信息的需求方面发挥了重要的作用.但是,由于各种搜索引擎所采用的技术和服务对象的不同,它们之间的各项性能差异很大.因此,通过对搜索引擎进行合理的评价,不仅有利于用户的选择与使用,而且有利于其本身的改进和发展.目前大多数评价方法主要以描述为主,通常只能对搜索引擎进行定性或部分定量描述,不能系统、全面的对不同搜索引擎进行综合评价.因此,建立搜索引擎综合评价体系,通过数学方法进行综合评价,具有较大的现实意义和应用前景.
4.会议论文 葛瑞平.许永龙 网络信息检索现状与性能评价研究 2004
伴随着Internet的迅速发展,网络成为一种重要的信息载体,有效的信息检索和网络检索工具的评价也成为网络信息管理的挑战和艰难任务。本文通过对网络信息特点的分析和网络信息检索工具的论述,得出了适应于网络信息检索工具的评价指标体系,同时分析出网络信息检索的现状中存在的问题,并给出相应的解决办法。
5.期刊论文 仵格娟 Internet搜索引擎概述及其未来发展 -情报杂志2002,21(9)
对基于Internet的搜索引擎的含义及分类、基本构成、工作原理及性能评价标准进行了概述,并进一步分析了利用搜索引擎检索网络信息的局限,对其未来的发展趋势作了相应的分析.
6.期刊论文 夏旭.李健康.方平 WWW网络信息资源搜索引擎的研究进展 -图书馆论坛2000,20(5)
19xx年杨致远等的YAHOO主题指南拉开了WWW网络信息检索的序幕,使得网络搜索引擎和主题指南的研究成为当前国内外研究的热点.对于国内外搜索引擎的比较研究、开发利用、搜索引擎的质量和性能评价、搜索引擎的选择等,均有大量文献报道.本文从以上几个方面综述其研究进展.
7.期刊论文 张秋霞 网络信息检索工具统计性能对比分析研究 -情报杂志2003,22(10)
针对网络信息检索工具的性能评价,结合统计学原理和统计方法,研究了网络检索工具性能对比分析研究的方法和指标体系,提出了网络信息检索工具对比分析研究的方法.
引证文献(2条)
1.岑荣伟.刘奕群.张敏.茹立云.马少平 网络检索用户行为可靠性分析[期刊论文]-软件学报 2010(5)
2.蔡岳.袁津生 用户行为聚类的搜索引擎算法与实现[期刊论文]-计算机系统应用 2010(4)
本文链接:http://d..cn/Periodical_rjxb200811023.aspx
授权使用:武汉大学(whdx),授权号:8561d7e8-013d-40ec-84e3-9e3300e6e6c8
下载时间:20xx年11月19日