
知识总结
1.插入,删除,修改(语法)
(插入)INSERT [INTO] <表名> [列名] VALUES <值列表>
(更新) UPDATE <表名> SET<列名> =<给列赋的新??>
[WHERE <更新条件>]
(删除)DELETE [FROM] <表名> [WHERE <删除条件>]
注意
插入语句
如果没有能很好的记住字段在表中的顺序最好是写上列名
2.条件查询
Select <列名>
From <表名>
Where <查询条件的表达式>
Order <排序的列名>
3给字段取别名 as 用法
使用AS 来为列其别名
Select 学号 as studentNO,姓名 as name ,家庭地址 as address
From studentinfo
Where 家庭地址<>‘黑龙江哈尔滨’
使用=来为列 另起别名
Select ‘姓名’=firstName+‘.’+lastname from employees
注意:1.+连接字符数据,结果为字符串数据的连接
2.如果+ 连接数值型,结果为数值的和
4.函数
字符串函数
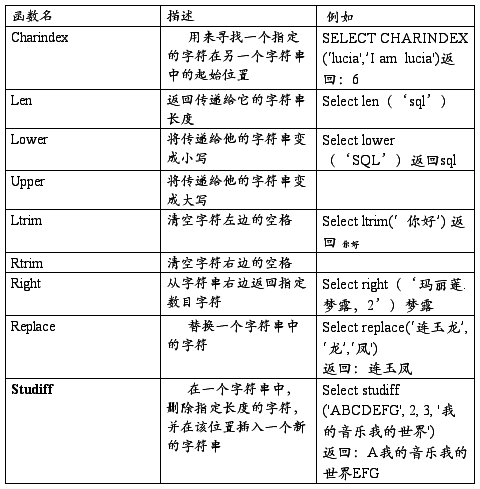

数学函数

备注:
日期函数中datediff可以用来计算时间差(例如,年龄) getdate()用来设置默认
这些函数容易记也容易忘,尤其是书写的格式规范。
5 like用法
*通配符
*%包含零个或更多字符串
*_(下划线)任何单个字符
*[]指定范围([a-f])或集合[abcdf]中任何的一个单个字符
*[^]不属于指定范围[a-f]或集合[abcdef]的任何单个字符
例
SELECT * FROM 数据表
WHERE 编号 LIKE ‘00[^8]%[AC]%’
可能会查询出的编号值为( a)。
A、0090ACD
B、007_AFF
C、008&DCG
D、008C
6.聚合函数
*Count(), * Max(),*Min(),*Avg(),sum()
6.1分组查询—group by—having
Select任职部门,count(*)
From lucia工作室
Where目前的薪资>=2000
Group by任职部门
Having count(*)>4
7.多表查询
*inner join内连接:两张表的顺序颠倒对结果没有影响
*left join左连接:左边的表是主表,表的顺序不能颠倒
*right join右连接:右边的表是主表,表的顺序不能颠倒
例
SELECT S.姓名,C.课程编号,C.笔试成绩
FROM StudentInfo AS S
INNER JOIN Score Info AS C
ON C.学号 = S.学号
8.建表的三大范式
v 第一范式的目标是确保每列的原子性
v 如果每列都是不可再分的最小数据单元(也称为最小的原子单元),则满足第一范式(1NF)
v
v 如果一个表中个字段关系满足1NF,并且除了主键以外的其它列,都依赖于该主键,则满足第二范式(2NF)
v 第二范式要求每个表只描述一件事情(去除不依赖主键或部分依赖主键的列)

由第二范式可知:产品价格不是依赖订单的编号
v 如果一个关系满足2NF,并且除了主键以外的其它列都不传递依赖于主键列,则满足第三范式(3NF)
v 第三范式的目标是确保每列都直接依赖主键
由第三范式可知:产品的结果是依赖产品编号而不是直接依赖订单编号的
9.主键(primary key),外键(foreign key) 创建/添加 语法
Constraint PK_ 主键名称 primary key(主键名称)
Constraint FK_外键的名称 foreign key(外键名称)
References 父表 (父表字段)
修改
Alter table 子表
Add Constraint FK_外键的名称 foreign key(外键名称)
References 父表 (父表字段)
10变量(局部变量,全局变量)
局部变量
*声明局部变量
DECLARE @变量名 数据类型
* 赋值
*SET @变量名= 值
*SELECT @变量名=值
全局变量
是系统的,是不能改变的
较常用的是:

11.if…… else ,while,case end, when then 用法例题
=============if else ===================
if exists (select *from sysobjects where name='NewTable')
drop table NewTable
select姓名,S.学号,笔试成绩,机试成绩,是否通过=case
when笔试成绩>60 and机试成绩>60 then 1
else 0
end
into NewTable from studentinfo as s
left join scoreinfo as c
on s.学号=c.学号
go
==============while===================
declare @writtenAvg decimal
declare @labavg decimal
select @writtenAvg= avg(笔试成绩) from studentscore
select @labavg=avg(机试成绩) from studentscore
if(@writtenAvg>@labavg)
begin
print('笔试成绩大于机试成绩')
while(1=1)
begin
update studentscore set机试成绩=机试成绩+1
if(select max(机试成绩)from studentscore)>=97
break
end
end
else
begin
print('机试成绩大于笔试成绩')
while(1=1)
begin
update studentscore set笔试成绩=笔试成绩+1
if(select max(笔试成绩) from studentscore)=97
break
end
end
go
select * from studentscore
go
============case end==============
select姓名,学号
,笔试成绩=
case
when笔试成绩 is null then'缺考'
else convert(varchar(5),笔试成绩)
end
,机试成绩=
case
when机试成绩 is null then'缺考'
else convert(varchar(5),机试成绩)
end
,是否通过=
case
when是否通过=1 then '是'
when是否通过=0 then'否'
end
from NewTable
go
===========when then =====================
if exists (select *from sysobjects where name='NewTable')
drop table NewTable
select姓名,S.学号,笔试成绩,机试成绩,是否通过=case
when笔试成绩>60 and机试成绩>60 then 1
else 0
end
into NewTable from studentinfo as s
left join scoreinfo as c
on s.学号=c.学号
go
select * from newTable
12子查询(in,exists)
SELECT 姓名 FROM StudentInfo
WHERE 学号
IN
(SELECT 学号 FROM ScoreInfo )
GO
注意:
基本上 in 可以等价于“=”可是“=”只能是子查询返回的是单个结果,如果是多个查询结果只能用 in
Exists用法用例:
IF EXISTS (SELECT * FROM sysdatabases WHERE name =‘LuciaBank')
DROP DATABASE LuciaBank
14存储过程
优点:
<1>执行的速度更快
<2>允许模块化程序设计
<3>提高系统安全性
<4>减少网络流通量
14.1分类
<1>系统存储过程
“sp_”或者是“XP_”
常用系统存储过程
Sp_database:列出服务器上的所有数据库
Sp_helpdb:报告有关指定数据库或所有数据库的信息
Sp_rename :更改数据库的名称
Sp_tables:返回当前环境下可查询的对象的列表
sp_columns:返回某个表列的信息
sp_help:查看某个表的所有信息
sp_helpconstraint:查看某个表的约束
sp_helpindex: 查看某个表的索引
sp_password: 添加或修改登录帐户的密码
sp_helptext: 显示默认值、未加密的存储过程、用户定义的存储过程、触发器或视图的实际文本
14.2自定义的存储过程
14.2.1定义存储过程的语法和调用的语法
<1>
CREATE PROC[EDURE] 存储过程名
@参数1 数据类型= 默认值OUTPUT,
…… ,
@参数n 数据类型= 默认值OUTPUT
AS
SQL语句
<2>
调用的语法
EXEC过程名[参数]
14.2.2不带参数的存储过程
/*------------------------------------------------------
存储过程(不带参数)
题目:查看本次考试的平均分数,并查看没有通过的学生的名单
----------------------------------------------------------*/
create procedure p_scoreInfo
as
declare @writtenAvg decimal
declare @labAvg decimal
select @writtenAvg=avg (笔试成绩),@labAvg=avg(机试成绩) from studentscore
print'笔试成绩的平均分'+convert(nvarchar(5),@writtenAvg)
print'机试成绩的平均分'+convert(nvarchar(5),@labAvg)
if(@writtenAvg>60 and @labAvg>60)
print'本班的成绩优秀'
else
print'本班的成绩很差'
print'-------------------------------------------------------'
print '本班成绩不及格的人名单'
select s.学号,姓名,笔试成绩,机试成绩
from studentinfo s, studentscore c
where s.学号=c.学号
and笔试成绩<60 or机试成绩<60
go
exec p_scoreInfo
go
14.2.3 带参数的存储过程
存储过程的参数分两种:输入参数,输出参数
例题
/*--------------------------------------------------------------
带参数的存储过程
题目:查看本次考试的平均分数,并查看没有通过的学生的名单
可以规定及格的分数
-----------------------------------------------------------------*/
create procedure proc_scoreinfoHaveParams
(
@writePass decimal ,--默认值是60
@labPass decimal
)
as
declare @writtenAvg decimal
declare @labAvg decimal
select @writtenAvg=avg (笔试成绩),@labAvg=avg(机试成绩) from studentscore
print'笔试成绩的平均分'+convert(nvarchar(5),@writtenAvg)
print'机试成绩的平均分'+convert(nvarchar(5),@labAvg)
if(@writtenAvg>@writePass and @labAvg>@labPass)
print'本班的成绩优秀'
else
print'本班的成绩很差'
print'-------------------------------------------------------'
print '本班成绩不及格的人名单'
select s.学号,姓名,笔试成绩,机试成绩
from studentinfo s, studentscore c
where s.学号=c.学号
and 笔试成绩<@writePass or 机试成绩<@labPass
go
exec proc_scoreinfoHaveParams 45,35
go
*--------------------------------------------------------------
带参数(输出)的存储过程
题目:查看本次考试的平均分数,并查看没有通过的学生的人数
-----------------------------------------------------------------*/
create procedure proc_outputscoreInfo
(
@sumNotPass int output,
@writePass decimal=60 ,--默认值是60
@labPass decimal=60
)
as
declare @writtenAvg decimal
declare @labAvg decimal
select @writtenAvg=avg (笔试成绩),@labAvg=avg(机试成绩) from studentscore
print'笔试成绩的平均分'+convert(nvarchar(5),@writtenAvg)
print'机试成绩的平均分'+convert(nvarchar(5),@labAvg)
if(@writtenAvg>@writePass and @labAvg>@labPass)
print'本班的成绩优秀'
else
print'本班的成绩很差'
print'-------------------------------------------------------'
select @sumNotPass=count(*) from studentscore where 笔试成绩<@writtenAvg or 机试成绩=@labAvg
go
declare @sum int
exec proc_outputscoreInfo @sum output, 35,35
print '***************************************'
if @sum>=3
print '本班成绩不及格的人数是'+convert(varchar(5),@sum)+'及格人太少,及格分数要在调低'
else
print'及格人数适中,及格分数线可以'
drop proc proc_outputscoreInfo
go
14.2.4RAISERROR用法
语法:
RAISERROR (msg_id| msg_str,severity, state WITH option[,...n]])
msg_id:在sysmessages系统表中指定用户定义错误信息
msg_str:用户定义的特定信息,最长255个字符
severity:定义严重性级别。用户可使用的级别为0?18级
state:表示错误的状态,1至127之间的值
option:指示是否将错误记录到服务器错误日志中
/*--------------------------------------------------------------
带参数(输出)的存储过程
题目:查看本次考试的平均分数,并查看没有通过的学生的人数
当输入的及格分数不再1到100之间则报错
-----------------------------------------------------------------*/
declare @sum int,@t int
exec proc_outputscoreInfo @sum output,80
set @t=@@error
print '错误号:'+convert(nvarchar(10),@t)
if @t<>0
raiserror('及格线错误,请重新输入(1——100之间)',16,1)
return
print '***************************************'
if @sum>=3
print '本班成绩不及格的人数是'+convert(varchar(5),@sum)+'及格人太少,及格分数要在调低'
else
print'及格人数适中,及格分数线可以'
drop proc proc_outputscoreInfo
go
15事物
15.1 事物概念
v 事务(TRANSACTION)是作为单个逻辑工作单元执行的一系列操作
v 这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行
v 事务是一个不可分割的工作逻辑单元
15.2事物四个属性
u 原子性(Atomicity):事务是一个完整的操作。
事务的各步操作是不可分的(原子的);要么都执行,要么都不执行
u 一致性(Consistency):当事务完成时,数据必须处于一致状态
u 隔离性(Isolation):对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务
u 永久性(Durability):事务完成后,它对数据库的修改被永久保持,事务日志能够保持事务的永久性
15.3管理事务T_SQL语句
<1> 开始事务: beigin transaction
<2> 提交事务:commit transaction
<3> 回滚事物: rollback transaction
15.4 判断出错的语句 @@ERROR
v 15.5事务的分类:
u 显性事务:用BEGIN TRANSACTION明确指定事务的开始,这是最常用的事务类型
u 隐性事务:通过设置SET IMPLICIT_TRANSACTIONS ON 语句,将隐性事务模式设置为打开,下一个语句自动启动一个新事务。当该事务完成时,再下一个 T-SQL 语句又将启动一个新事务
u 自动提交事务:这是 SQL Server 的默认模式,它将每条单独的 T-SQL 语句视为一个事务,如果成功执行,则自动提交;如果错误,则自动回滚
15.6例题
---------------------------------
--转账事物处理
--------------------------------
begin transaction
declare @errorcount int
set @errorcount=0
update clientAccount set 余额=余额-1000
where 账号='6226900707220987'
set @errorcount=@errorcount+@@error
update clientAccount set 余额=余额+1000
WHERE 账号='6226900707220654'
set @errorcount=@errorcount+@@error
if @errorcount<>0
begin
print'交易失败,回滚事物'
rollback transaction
end
else
begin
print '交易成功'
commit transaction
end
go
print'查看转账事物后余额'
select * from BankAccount
go
16索引(提高查询速度,但是占空间) 是SQL Server编排数据的内部方法
16.1索引的类型
v 唯一索引:唯一索引不允许两行具有相同的索引值
v 主键索引:为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的,并且不能为空
v 聚集索引(Clustered):表中各行的物理顺序与键值的逻辑(索引)顺序相同,每个表只能有一个
v 非聚集索引(Non-clustered):非聚集索引指定表的逻辑顺序。数据存储在一个位置,索引存储在另一个位置,索引中包含指向数据存储位置的指针。可以有多个,小于249个
16.2 语法
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
INDEX index_name
ON table_name (column_name…)
[WITH FILLFACTOR=x]
<1>UNIQUE表示唯一索引,可选
<2>CLUSTERED、NONCLUSTERED表示聚集索引还是
非聚集索引,可选
<3>FILLFACTOR表示填充因子,指定一个0到100之间的值,
<4>值指示索引页填满的空间所占的百分比
16.3索引创建的指定原则
v 请按照下列标准选择建立索引的列
u 该列用于频繁搜索
u 该列用于对数据进行排序
v 请不要使用下面的列创建索引:
u 列中仅包含几个不同的值
u 表中仅包含几行。为小型表创建索引可能不太划算,因为SQL Server在索引中搜索数据所花的时间比在表中逐行搜索所花的时间更长
17视图
概念:视图是一张虚拟表,它表示一张表的部分数据或多张表的综合数据,其结构和数据是建立在对表的查询基础上
17.1视图的用途
u 筛选表中的行
u 防止未经许可的用户访问敏感数据
u 降低数据库的复杂程度
u 将多个物理数据库抽象为一个逻辑数据库
17.2语法
CREATE VIEW view_name
AS
17.3例题
-------------------------------------------------
----创建CS_KC视图,包括雇员名字,部门名字、其选修的课程号及成绩收入在—之间的雇员号码
--------------------------------------------------
create view CS_KC as
select e.name as 顾员姓名,
d.departmentname as 部门名称,
e.EmployeeID as 雇员编号
from Employees as e ,Departments as d,Salary as s
where s.Income between 20## and 3000 and e.departmentID=d.departmentID and e.employeeID=s.employeeID
18触发器
触发器是一种特殊的存储过程,类似于事件函数,SQL Server 允许为 INSERT、UPDATE、DELETE 创建触发器,即当在表中插入、更新、删除记录时,触发一个或一系列 T-SQL语句。
18.1 语法
创建触发器用 :CREATE TRIGGER
CREATE TRIGGER 触发器名称
ON 表名
FOR INSERT、UPDATE 或 DELETE
AS
T-SQL 语句
18.2触发器中用到两个临时表:Deleted 和Inserted
一个数据库系统中有两个虚拟表用于存储在表中记录改动的信息,分别是:
Deleted ,Inserted
虚拟表Inserted
u 表记录新增时,用来存放新增的数据记录
u 表记录更新时,用来存放更新的新记录
u 表记录删除时,不存储任何信息
虚拟表Deleted
u 表记录新增时,不存放任何记录
u 表记录更新时,用来存放更新前的记录
u 表记录删除时,用来存放删除前的数据记录
18.4例题
-----------------------------------------------------------
--修改Departments表departmentID字段值时,该字段在Employees表中的对应值也应修改;
-----------------------------------------------------------------
create trigger deparmentsudate on departments
for update
as
begin
if(columns_updated()&01)>0
update employees
set departmentID=(select ins.departmentID from inserted ins)
where departmentID=(select departmentID from deleted)
end
------------------------------------------------------
----1.向Employees表添加一记录时,该记录的departmentID值在
--Departments表中应存在create trigger employeesinsert on employees
-------------------------------------------------------------
create trigger employeesinsert on employees
for insert update
as
begin
if((select ins.departmentid from inserted ins) not in(select departmentid from departments))
rollback
end
---------------------------------------------------------------------
---1.3. 删除Departments表中一记录时,该记录departmentID字段值在Employees表中对应的记录也应删除
---------------------------------------------------------------------
create trigger departmentsdelete on departments
for delete
as
begin
delete from employees
where departmentID=(select departmentID from deleted)
end
go